- Swift Algorithms & Data Structures
- Introduction
- 1. Big O Notation
- 2. Sorting
- 3. Linked Lists
- 4. Generics
- 5. Binary Search Trees
- 6. Tree Balancing
- 7. Tries
- 8. Stacks & Queues
- 9. Graphs
- 10. Shortest Paths
- 11. Heaps
- 12. Traversals
- 13. Hash Tables
- 14. Dijkstra Algorithm Version 1
- 15. Dijkstra Algorithm Version 2
Hash Tables
A hash table is a data structure that groups values to a key. As we've seen, structures like graphs, tries and linked lists follow this widely-adopted model. In some cases, built-in Swift data types like dictionaries also accomplish the same goal. In this essay, we'll examine the advantages of hash tables and will build our own custom hash table model in Swift.
Keys & Values
As noted, there are numerous data structures that group values to a key. By definition, linked lists provide a straightforward way to associate related items. While the advantage of linked lists is flexibility, their downside is lack of speed. Since the only way to search a list is to traverse the entire set, their efficiency is typically limited to O(n). To constrast, a dictionary associates a value to a user-defined key. This helps pinpoint operations to specific entries. As a result, dictionary operations are typically O(1).
The Basics
As the name implies, a hash table consists of two parts - a key and value. However, unlike a dictionary, the key is a "calculated" sequence of numbers and / or characters. The output is known as a "hash". The mechanism that creates a hash is known as a hash algorithm.
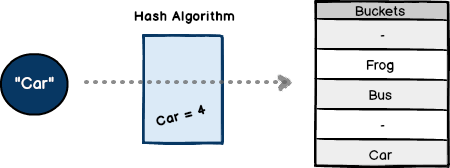
The following illustrates the components of a hash table. Using an array, values are stored in non-contiguous slots called buckets. The position of each value is computed by the hash function. As we'll see, most algorithms use their content to create a unique hash. In this example, the input of "Car" always produces the key result of 4.
The Data Structure
Here's a hash table data structure written in Swift. At first glance, we see the structure resembles a linked list. In a production environment, our HashNode could represent any combination of items, including custom objects. Additionally, there is no member property for storing a key.
//simple example of a hash table node
class HashNode {
var firstname: String!
var lastname: String!
var next: HashNode!
}
The Buckets
Before using our table we must first define a bucket structure. If you recall, buckets are used to group node items. Since items will be stored in a non-contiguous fashion, we must first define our collection size. In Swift, this can be achieved with the following:
class HashTable {
private var buckets: Array<HashNode!>
//initialize the buckets with nil values
init(capacity: Int) {
self.buckets = Array<HashNode!>(count: capacity, repeatedValue:nil)
}
}
Adding Words
With the components in place, we can code a process for adding words. The addWord method starts by concatenating its parameters as a single string (e.g.,fullname). The result is then passed to the createHash helper function which subsequently, returns an Int. Once complete, we conduct a simple check for an existing entry.
//add the value using a specified hash
func addWord(firstname: String, lastname: String) {
var hashindex: Int!
var fullname: String!
//create a hashvalue using the complete name
fullname = firstname + lastname
hashindex = self.createHash(fullname)
var childToUse: HashNode = HashNode()
var head: HashNode!
childToUse.firstname = firstname
childToUse.lastname = lastname
//check for an existing bucket
if (buckets[hashindex] == nil) {
buckets[hashindex] = childToUse
}
Hashing and Chaining
The key to effective hash tables is their hash functions. The createHash method is a straightforward algorithm that employs modular math. The goal? Compute an index.
//compute the hash value to be used
func createHash(fullname: String) -> Int! {
var remainder: Int = 0
var divisor: Int = 0
//obtain the ascii value of each character
for key in fullname.unicodeScalars {
divisor += Int(key.value)
}
remainder = divisor % buckets.count
return remainder
}
With any hash algorithm, the aim is to create enough complexity to eliminate "collisions". A collision occurs when different inputs compute to the same hash. With our process, Albert Einstein and Andrew Collins will produce the same value (e.g., 8). In computer science, hash algorithms are considered more art than science. As a result, sophisticated functions have the potential to reduce collisions. Regardless, there are many techniques for creating unique hash values.
To handle collisions we'll use a technique called separate chaining. This will allow us to share a common index by implementing a linked list. With a collision solution in place, let's revisit the addWord method:
//add the value using a specified hash
func addWord(firstname: String, lastname: String) {
var hashindex: Int!
var fullname: String!
//create a hashvalue using the complete name
fullname = firstname + lastname
hashindex = self.createHash(fullname)
var childToUse: HashNode = HashNode()
var head: HashNode!
childToUse.firstname = firstname
childToUse.lastname = lastname
//check for an existing bucket
if (buckets[hashindex] == nil) {
buckets[hashindex] = childToUse
}
else {
println("a collision occured. implementing chaining..")
head = buckets[hashindex]
//append new item to the head of the list
childToUse.next = head
head = childToUse
//update the chained list
buckets[hashindex] = head
}
} //end function